결제용 QR 코드는 단순히 일회용 토큰으로만 구성될 수 있지만, 로컬 생성 결제 토큰처럼 사용자 ID나 결제 수단 정보 등 추가적인 데이터가 충분히 담길 수 있어요. 네이버 페이에서 사용되고 있는 EMV-QR 표준은 이미 탬플릿 지시자나 결제 수단 정보(Track 2 Equivalent Data)와 인증 코드 같은 부가 정보를 담고 있어요.
하지만 QR 코드로 전달할 수 있는 데이터의 양은 훨씬 제한적이에요. 이론상 가장 큰 QR 코드는 약 2,900자 까지 담을 수 있지만, 이 경우 QR 코드의 크기가 너무 거대해져서 특히 모바일 앱에서 사용하기엔 적절하지 않아요. 바코드도 하나의 디자인 요소로 볼 수 있기 때문에 QR 코드의 크기에 대한 제한도 필요해요.
특히 로컬 생성 결제 토큰은 사용자 기기에서 일회용 인증코드를 생성하기 때문에 더 많은 정보를 담을 수 있다면 더 높은 수준의 보안 장치를 사용할 수 있어요. 그래서 QR 코드의 크기를 줄이기 위해 노력할 가치가 충분히 있죠. 이번 글에선 이런 고민들을 제가 어떻게 해결했고, 더 작은 QR 코드로 더 많은 정보를 저장하기 위해 어떤 방법을 사용할 수 있는지 설명해보려 해요.
QR 뜯어보기
본론으로 들어가기 전에 오류 정정 레벨(error correction level)과 버전(version)을 먼저 살펴볼게요. QR 코드의 크기와 직접적인 연관이 있기도 하고, QR 코드를 만들 때 고려해야 하는 요소이기 때문이에요.
오류 정정 레벨 (Error Correction Level)
오류 정정 레벨(error correction level)은 손상된 QR 코드를 읽을 수 있게 도와주는 장치예요. 어릴 때 수학 문제집에 있는 강의 QR 코드를 연필로 색칠해 본 적이 있는데 그래도 인식되었던 게 정말 신기했었어요. 그땐 그냥 모든 점들이 데이터를 나타내는 게 아니라고 생각했었는데, 사실 오류 정정 기능 덕분이었던 거죠. 저만 이런 적 있는 건 아니죠? 😜
오류 정정 레벨은 L(low), M(medium), Q(quartile), H(high)의 네 가지가 종류가 있어요. 복구 수준은 각각 최대 7%, 15%, 25%, 30%예요. 오류 정정 레벨이 높을수록 바코드의 크기도 커져요. 작은 QR 코드에 더 많은 정보를 넣으려면 더 낮은 레벨을 사용해야 해요. 그런데 우리는 결제 QR 코드를 휴대폰 스크린에 나타내죠. 연필로 QR 코드를 망가뜨리는 사람도 없지 않을까요?
"스크린이 박살 난 경우에 좋겠어요!"
맞아요. 스크린이 QR 코드의 모듈을 표현할 수 없을 정도로 고장 났을 때 도움이 될 수 있어요. 하지만 냉정하게 생각해 보면 우리가 스크린이 심하게 고장 난 경우까지 생각할 필요가 없다고 볼 수도 있어요. 근데 이런 경우에도 결제를 성공적으로 진행할 수 있다면 사용자에게 감동을 줄 수 있을거예요. 이와 관련된 깊은 논의는 비즈니스 요구사항과 직접 연결되는 부분이기 때문에 요구 사항에 따라 결정하면 돼요.
저는 밝기 조절이 불가능할 때 더 좋은 장치가 될 것 같다고 생각해요. 대부분의 QR 간편 결제 앱은 QR 또는 바코드를 표시할 때 화면 밝기를 높이는 기능을 가지고 있어요. 화면을 밝기를 높이는 이유는 바코드의 흑백을 뚜렷하게 나타내어 인식률을 높이기 위해서예요. 하지만 배터리가 일정 수준이하로 내려가면 밝기를 높일 수 없게 되고, 인식률이 떨어질 수 있어요. 그래서 평소엔 가장 낮은 레벨인 L레벨을 사용하고, 밝기를 올릴 수 없을 때만 Q 또는 H레벨을 사용하여 인식률을 높이도록 최적화할 수 있어요. 하지만 이건 경험에 의한 예상이라 기회가 된다면 더 정교한 실험으로 정말 도움이 되는지 확인해보고 싶어요.
버전
QR 코드는 크기에 따라 1에서 40까지의 버전으로 구분돼요. QR 코드에 있는 작은 점 하나를 모듈이라고 하는데, 버전 1은 가로 세로 21개의 모듈로 이루어지고, 버전이 높아질 때마다 모듈은 4개씩 늘어나요. 버전이 늘어날수록 QR 코드의 크기가 커져서 저장할 수 있는 비트 수는 늘어나지만, 같은 크기의 이미지에선 모듈의 크기가 점점 작아지기 때문에 적당한 한계를 정해야 해요.
QR이 버전별로 어떻게 생겼는지 한번 볼게요. 순서대로 버전 6, 13, 20이에요.



다음 QR 마다 정렬 패턴(Alignment pattern)의 개수가 점점 늘어나고 있어요. 정렬 패턴은 정확한 인식을 위해 사용되는 패턴으로, 버전 2~6에는 1개, 7~13엔 6개, 그리고 버전 14~20에는 13개가 존재해요.
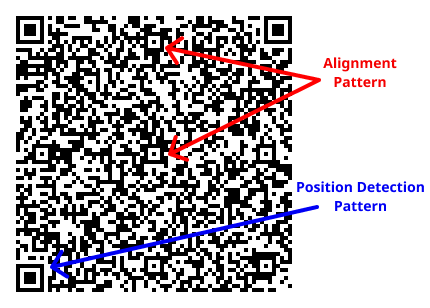
정렬 패턴이 6개 일 때까진 나쁘지 않지만, 13개가 되기 시작하니 너무 부담스럽게 느껴지지 않나요? 버전 20은 작은 QR 코드가 9개 모여있는 것처럼 보여요. 휴대폰에서 나타내기엔 너무 큰 것 같고, 이는 낮은 인식률로 연결돼요.
실제로 보면 더 끔찍해요.

저희 매점에서 사용하는 리더기로 테스트해봤을 때 버전 14 이상의 QR은 인식이 되지 않거나 잘 되지 않았어요.
그래서 저는 "6개의 정렬 패턴을 가지는 버전 13을 넘기지 않는다"라는 규칙을 정했어요.
바이너리 QR
이제 본론으로 들어갈게요. QR 코드에 바이너리 값을 그냥 담을 순 없어요. 따지고 보면 바이너리 값을 저장하는 게 맞지만, 기본적으로 QR 코드의 데이터는 문자로 인코딩 되기 때문에 일반적인 바코드 리더기는 QR 코드를 읽을 때 바이너리 값을 어떤 문자에 대응시키려 할 거예요. 만약 바이너리가 인쇄할 수 없는 문자 또는 정의되지 않은 값에 대응되거나 우리와 리더기와 서로 다른 문자 집합을 사용한다면 데이터는 변형되거나 손실될 수 있어요. 그래서 바이너리를 적절히 인코딩하는 과정이 반드시 선행돼야 해요.
모드
QR 코드에선 사용하는 문자 집합(character set)을 "모드"로 구분해요. 여러 모드를 사용하는 이유는 문자 집합의 크기가 작을수록 글자당 차지하는 비트수도 작아져서 경우에 따라 최적화된 QR 코드를 만들 수 있기 때문이에요.
예를 들어 우리가 16진수 문자열을 나타낸다고 하면, 16개의 문자만 필요하니 한 문자를 나타내려면 4비트만 있어도 돼요. 한 문자당 7비트를 차지하는 아스키코드를 사용한다면 데이터가 불필요하게 커질 거예요. 이런 이유로 다양한 모드를 사용할 수 있도록 설계됐어요.
QR 코드에선 숫자, 영숫자, 바이트, 그리고 한자 모드를 사용할 수 있어요.
| 모드 | 글자 당 비트 수 |
| 숫자 모드 (Numeric) | 3⅓ 비트 (3글자 당 10비트) |
| 영숫자 모드(Alphanumeric) | 5½ 비트 (2글자당 11비트) |
| 바이트 모드 (Byte) | 8 비트 |
| 한자 모드 (Kanji) | 13 비트 |
헷갈리면 안 되는게 있어요. 글자 당 비트 수에서 비트는 우리가 저장하려는 바이너리의 크기를 뜻하는게 아니라, QR 내부에 저장되는 비트 수를 뜻해요. 만약 바이너리 값을 그대로 저장한다면 전체 비트 수 만큰 저장할 수 있지만, 그러면 안되는 이유를 위에서 언급했어요. 바이너리를 모드에 따라 인코딩한 후, 인코딩 된 문자열의 길이에 위 값을 곱하고 저장 가능한 최대 비트 수와 비교하면 어떤 버전으로 표현할 수 있는지 알 수 있어요. 다행히 이미 모드와 오류 정정 레벨에 따라 버전에서 저장 가능한 최대 글자수가 정리되어 있기 때문에 더 쉽게 비교할 수 있어요.
이제 각 모드 별로 사용하는 문자 집합과 바이너리 값을 모드에 맞게 표현하는 방법을 자세히 살펴볼게요.
숫자 모드
숫자 모드는 0에서 9까지 아라비아 숫자를 사용해요. 주어진 수를 세 그룹으로 묶고 각 그룹을 10비트의 이진수로 전환해요. 마지막 그룹이 두 개 또는 한 개의 숫자로 이루어지면 각각 4비트와 7비트의 이진수로 전환해요.
마지막 그룹에 대한 예외 상황을 제외한다면 저장 효율성은 \(\frac{3\log_2 10}{10}\times100\%=99.66\%\) 예요.
"왜 \(\log_2 10\) 인가요?"
만약 우리에게 2비트가 있다면 우리는 4(\(2^2\))개의 서로 다른 문자를 나타낼 수 있고, 4비트가 있다면 16(\(2^4\))개의 문자를 나타낼 수 있어요. 그럼 반대로 4개의 서로다른 문자를 나타내려면 몇 비트가 필요한지 어떻게 알아낼까요? 로그를 이용하여 2(\(\log_2 4\)) 비트가 필요하다는 걸 알 수 있어요. 그래서 우리에게 10개의 문자가 있으면 \(\log_2 10 \approx 3.322\) 비트가 필요해요.
만약 문자가 8개뿐이라면 바이너리를 8비트씩 읽어 문자에 대응시키면 되기 때문에 간단하고 빠르게 인코딩할 수 있어요. 하지만 문자의 수가 2의 제곱수가 아니라면 다른 방법으로 인코딩을 해야해요. 한가지 방법은 모든 바이너리 값을 하나의 bigint로 보고 진법을 바꾸는 방법이에요. 이 방법은 바이너리 값이 작을 땐 괜찮지만, 값이 64비트로 표현할 수 없을 정도로 크다면 계산하는데 더 큰 비용이 들게돼요(다른 라이브러리를 사용하는 등). 그래서 주로 바이너리 값을 64비트 이하의 청크(chunk)로 나누어 계산해요.
아래 표는 청크를 1바이트씩 늘려가며 청크 당 문자열의 길이와 효율성을 나타낸 표예요.
| chunk size | length | efficiency |
| 1 byte | 3 | 80% |
| 2 bytes | 5 | 96% |
| 3 bytes | 8 | 90% |
| 4 bytes | 10 | 96% |
| 5 bytes | 13 | 92.3% |
| 6 bytes | 15 | 96% |
| 7 bytes | 17 | 98.82% |
| 8 bytes | 20 | 96% |
청크를 1바이트로 나누면 사용하는 문자가 8개 뿐이라 가장 낮은 효율성을 가지고 있어요. 대신 7바이트로 나누어 17자로 나타내면, 가장 높은 효율성을 가지게 돼요. 대신 마지막 청크가 1에서 6바이트일 경우를 모두 처리해야 하기 때문에 인코딩 과정이 조금 복잡할 거예요.
length 계산 방법
2바이트(16비트)로 나타낼 수 있는 가장 큰 숫자는 65,535(\((1\ll16)-1\))이에요. 가장 큰 수가 5자리이기 때문에 모든 청크는 5자리로 변환되어야 해요. 그래서 7바이트의 경우 가장 큰 수는 72,057,594,037,927,935(\((1\ll56)-1\))라서 17자리예요.
efficiency 계산 방법: \(\frac{(chunk\ bits)}{(bits\ per\ char)\times(length)}\times100\%\)
2 바이트의 효율성: \(\frac{48}{\frac{10}{3}\times15}\times100\%=96\%\)
7 바이트의 효율성: \(\frac{56}{\frac{10}{3}\times17}\times100\%=98.82\%\)
인코딩
인코딩 방법은 주어진 데이터를 7바이트씩 읽고, 이를 10진수로 변환한 다음, 17자리가 되도록 0으로 패딩을 붙여줘요. 마지막 청크가 7바이트가 아닌 경우는 위 표에 나온 바이트 별 자릿수를 참고하여 변환해 주면 돼요. 구현상의 편의를 위해 각 바이트는 big-endian으로 읽어요. 이제부터 이 방법은 base10이라고 부를게요.

영숫자 모드
영숫자(alphanumeric) 모드는 0부터 9, 대문자 A부터 Z, 그리고 특수문자 9개로 45개의 문자를 사용하고, 문자 두 개당 11비트로 변환해요. 숫자 모드처럼 최대 효율성을 계산해 보면 \(\frac{2\log_2 45}{11}\times100\%=99.85\%\) 예요. 숫자 모드보다 조금 더 효율성이 좋지만, 청크로 나눴을 땐 효율성이 얼마인지 계산해 볼게요.
| chunk size | length | efficiency |
| 1 byte | 2 | 72.72% |
| 2 bytes | 3 | 96.96% |
| 3 bytes | 5 | 87.27% |
| 4 bytes | 6 | 96.96% |
| 5 bytes | 8 | 90.90% |
| 6 bytes | 9 | 96.96% |
| 7 bytes | 11 | 92.56% |
| 8 bytes | 12 | 96.96% |
2, 4, 6, 8 바이트로 나누었을 때 가장 높은 효율성을 가져요. 실제 효율성은 base10보다 조금 작아요. 인코딩 과정을 간단히 유지하기 위해 2바이트 청크를 사용할게요. 마지막 청크가 1바이트인 예외 상황만 처리해 주면 되니까요.
인코딩
2바이트씩 나누고, 이를 3자리의 45진수로 변환한 다음, 문자표에 대응하는 값으로 치환해 주면 돼요. 마지막 청크가 1 바이트면 2자리 45진수로 바꾸면 돼요. 구현상 편의를 위해 little-endian으로 읽어요.

base-45
base45는 RFC9285에 정의되어 있어요. QR 코드에서 효율적인 바이너리 값을 표현하기 위해 만들어졌다고 하는데, 위 계산 결과에서 알 수 있듯, 효율성 자체는 숫자모드를 사용하는 게 더 좋다는 걸 확인했어요. 그래도 정말 base45가 가장 효율적인지에 대한 논의는 아래에서 자세히 다뤄볼게요.
base-32, base-36
영숫자 모드에서 사용하는 문자열은 모두 ASCII 코드에도 포함된 문자예요. 그리고 웬만한 리더기는 ASCII 코드에서 인쇄가능한 문자를 지원할 거예요. 그러나 만약 QR 코드의 내용을 사람이 읽거나 쓰는 상황을 고려해야 한다면(병원의 환자 관리 번호나 부품의 일련번호 등) 공백, :(콜론), ;(세미콜론), `(백틱) 같은 특수 문자를 사용하고 싶지 않을 수도 있어요. 그럴 땐 base45의 대안으로 숫자와 대문자만, 그리고 일부 특수문자만 사용하는 base-32나 base-36을 고려해 볼 수 있어요.
바이트 모드
바이트 모드를 사용하면 이론상 바이너리 값을 그대로 저장해도 괜찮긴 해요. 하지만 특수한 경우가 아니라면 모든 QR 코드 리더기는 QR 코드의 바이너리 값을 문자열로 읽을 거예요. 처음에 말한 내용이에요. 현재 사양에선 바이트 모드가 ISO/IEC 8859-1 문자 집합을 사용하고, 한 문자당 8비트의 공간을 차지한다고 명시돼 있어요. 이 문자 집합에는 숫자와 영어 대소문자, 그리고 특수기호와 일부 라틴문자가 포함되어 있고, 일부분은 정의되지 않았어요. 제어 코드를 제외한 출력 가능한 문자는 총 205개예요. 그래서 임의의 바이너리 값을 그대로 저장하면 제어 문자나 정의되지 않은 코드에 대응되어 데이터가 손실될 수 있어요.
그렇다고 이 205개의 문자를 모두 사용하여 인코딩할 수도 없어요. 그 이유는 2000년에 만들어진 초기 사양에선 바이트 모드를 JIS X 0201로 해석한다고 명시되어 있어서 만약 이 사양을 따르는 리더기라면 데이터가 변형되기 때문이에요. 그뿐만 아니라 최신 리더기라도 ISO/IEC 8859-1을 사용하는지 확인해야 해요. 그러나 안타깝게도 저희가 사용하는 리더기를 포함해 대부분의 바코드 리더기는 ASCII 코드를 기본값으로 사용해요. 설정을 바꿔볼 수 있겠지만, 리더기 설정이 초기화되는 경우, 매장에서 원인을 파악하고 고치는 건 아주 어려울 거예요. 그래서 JIS X 0201과 ISO/IEC 8859-1, 그리고 ASCII 코드의 하위 호환성을 위해 US-ASCII 코드의 인쇄가능한 94개의 문자(33~126)를 이용해야 해요.
JIS X 0201과 ISO/IEC 8859-1는 아스키코드와 호환돼요.
base 64
ASCII 코드를 사용하는 대표적인 인코딩 방법으로 base64가 있어요. 그리고 EMV-CPM QR도 16진수 결괏값을 base64로 인코딩하라고 명시하고 있기 때문에 base64도 함께 비교해 볼게요.
base 64는 3바이트를 4개의 문자로 나타내는데, 4개의 문자는 바이트 모드에서 4바이트로 표현돼요. 따라서 효율성은 75%가 되죠. 다른 인코딩 방법과 비교해 보면 그리 좋은 수치는 아니지만, 많은 프로그래밍 언어에서 base64 인코딩을 지원하기 때문에 쉽게 사용할 수 있다는 장점이 있어요.
base 94
| chunk size | length | efficiency |
| 1 byte | 2 | 50% |
| 2 bytes | 3 | 66.6% |
| 3 bytes | 4 | 75% |
| 4 bytes | 5 | 80% |
| 5 bytes | 7 | 71.43% |
| 6 bytes | 8 | 75% |
| 7 bytes | 9 | 77.78% |
| 8 bytes | 10 | 80% |
4바이트와 8바이트에서 80%로 가장 높은 효율성을 보여줘요. 숫자와 영숫자 모드는 문자 집합의 모든 문자를 사용할 수 있었지만, 바이트 모드는 지원하는 모든 문자를 사용할 수 없어 효율성이 비교적 낮다는 걸 확인할 수 있어요. base64보단 높지만, 다른 모드와 비교해서 보면 아쉬운 수치예요. 하지만 가장 짧은 문자열로 인코딩할 수 있는 방법이에요.
마지막 청크에 대한 예외 상황의 수를 줄이기 위해 4바이트 청크를 사용할 거예요.
인코딩
base94도 다른 방법과 같은 메커니즘으로 변환해요.

평가
지금까지 살펴본 base64와 모드 별 가장 좋은 효율성을 가지는 경우를 정리해 볼게요.
- base10: 7바이트를 17글자로 나타내고 98.82%의 저장 효율성을 가짐.
- base45: 2바이트를 3글자로 나타내고 96.96%의 저장 효율성을 가짐.
- base64: 3바이트를 4글자로 나타내고 75%의 저장 효율성을 가짐.
- base94: 4바이트를 5글자로 나타내고 80%의 저장 효율성을 가짐.
| base | 바이트 당 글자 수 | 글자 당 바이트 수 | 효율성 |
| 10 | 2.43 | 0.411 | 98.82% |
| 45 | 1.5 | 0.667 | 96.96% |
| 64 | 1.33 | 0.75 | 75% |
| 94 | 1.25 | 0.800 | 80% |
이 지표만으론 어떤 인코딩이 가장 효율적인지 아직 알기 어려워요. 효율성 자체는 base10이 가장 우수하고, 인코딩 효율은 base94가 가장 우수해요. 그래서 실제 바이트를 저장할 때 어떤 인코딩이 가장 좋은지 계산해 봤어요.
바이트별 지표
첫 번째 표는 더 작은 버전으로 나타내는 인코딩을 우선으로 선택하고 그중 가장 짧은 인코딩 결과를 가지는 인코딩 방법을 선택했을 때예요. 전체 표는 너무 크기 때문에 링크(작은 버전 우선)로 첨부할게요.
| bytes | version | best | length |
| 1 | 1 | base45, base64, base94 | 2 |
| 2 | 1 | base45, base64, base94 | 3 |
| 3 | 1 | base64, base94 | 4 |
| 10 | 1 | base94 | 13 |
| 20 | 2 | base94 | 25 |
| 30 | 2 | base45 | 45 |
| 50 | 3 | base45 | 75 |
결과가 꾀나 흥미로워요. 데이터 크기가 10 바이트 이하일 땐 base64가 효율적인 경우도 있었고 여러 방법이 골고루 나타났어요. 그리고 base94와 base45가 번갈아가며 나타났고, 버전 6부턴 base45가 거의 항상 최적이었어요. base10은 같은 버전에서 더 많은 데이터를 담을 수 있기 때문에 사실상 비교 대상이 없어 버전 버전의 후반부 용량에서 자주 등장했는데, 만약 비교 대상이 없는 경우를 제외하면 base94가 최적일 거예요. 이로써 base45가 바이너리를 QR 코드에 나타내기 대개 적합한 방법인걸 확실하게 알 수 있었어요.
인코딩 길이
인코딩 길이를 기준으로도 비교해 봤어요. 짧은 인코딩 길이를 우선으로 선택하고 그중 더 작은 버전을 갖는 인코딩을 뽑았어요. 표는 링크(작은 길이 우선)에서 확인하실 수 있어요.
| byte | version | best | length |
| 10 | 1 | base94 | 13 |
| 20 | 2 | base94 | 25 |
| 30 | 3 | base94 | 38 |
| 50 | 4 | base94 | 63 |
초반엔 전 결과처럼 변동이 많았지만, 예상했듯이 base94가 항상 가장 짧은 길이를 산출했어요. 버전 40을 넘어가면서 더 이상 base94를 사용할 수 없게 되자 base45가 자리를 차지했고, 마지막으로 더 많은 내용을 저장할 수 있는 base10이 나타났어요.
base10 인코딩과 버전 40을 사용하면 최대 2919 바이트를 7089자로 QR코드에 담을 수 있어요. 작은 svg파일 하나 정도 저장할 수 있네요. 그런데 실제로 QR 코드로 2KB짜리 데이터를 담아야 한다면 접근 방법을 다시 생각해보는게 좋을거예요.
상황마다 예외가 존재하지만, QR 크기를 최대한 작게 만들고 싶으면 base45, 인코딩 길이를 최대한 작게 만들고 싶으면 base94를 사용하는 게 좋아요.
늘어난 용량
버전 13에서 오류 정정 레벨이 L일때 바이트 모드는 425자까지 저장할 수 있고, base64는 425자로 318바이트를 저장할 수 있어요. 반면 영숫자 모드는 619자 까지 저장할 수 있고, base45는 619자로 412바이트를 저장할 수 있어요.
base45덕분에 우린 94바이트나 더 저장할 수 있게 됐어요!
진짜 그런지 확인해 보기
말로만 base45가 짱이라고 하지 말고 진짜 그런지 눈으로 확인해 봐요.
로컬 생성 결제 토큰 예시인 114 바이트짜리 바이너리를 네 가지 인코딩을 이용해서 QR로 만들어 볼게요.
hex: 44501218320fae039d724c19816d2c2d1d5b7ca20c2cabcdc0825308f3881996f95c87e02c32591c50254204fd938cd023d91c0b86cbf1a938f11574e3def288502aa1c5bd9696a79b9cae23281271a4614c9d783c332730faa11ca3ba324c02ef3a0fb91aab0511613e54692e17312c5b2f
- base10: 1922833706189201401017539158704493124345030874649721257379916168064868548062829173895630989895382016371858283561161936361110905777942953160276731534947703836874086558863042405533297025832051915004017780401694474202111209246085146390228794044256488401841611754425927763178823343
- base45: SS8.C2ZE6.:LV+J-R9DGGEQ50W31YFBO1GWL7FOGMAJZUPA3QNV:7HJQ5.BB.5APF8P2W3 H.N4OO3$1HZOU.872W2E SXTU26ADKKO/N22JBUJT0M/25MGENDC$+JLR7..4 UV-R3BONIR9.AUK:1WG3$S09DC9UA9$5X96XNB
- base64: RFASGDIPrgOdckwZgW0sLR1bfKIMLKvNwIJTCPOIGZb5XIfgLDJZHFAlQgT9k4zQI9kcC4bL8ak48RV0497yiFAqocW9lpanm5yuIygScaRhTJ14PDMnMPqhHKO6MkwC7zoPuRqrBRFhPlRpLhcxLFsv
- base94: '%mr`/p!4h+H">oBxJ?m<Mp~='V-wZ#+XTCJur0@U{,xWV3ffO*W(t52#.'OW`}*c(r#l{=i527-q9o{Q>y=62$aTfIHu8JBk0IZ)MMDv5iK~x-.RSqVS[$"I"-5GT*S`e&nQ8u5=k~u*@]#




이 경우, 가장 작은 버전과 그중 가장 짧은 인코딩 길이를 갖는 base45가 가장 효율적이에요.
또 다른 예제로 네이버 페이에서 가져온 EMV-QR에 여러 인코딩을 적용해서 다시 QR 코드로 나타내봤어요. EMV-QR 사양에는 결괏값을 base64로 인코딩하라고 명시되어 있으니 base64에 주목해서 비교해 보세요. 제 카드 정보는 더미 값으로 대체했어요.
hex: 85054350563031616f4f07d410000001401057131234123412341234d12341234123412341234f5f3401029f6012832cfdd5f3cb3c6a58ac07a45d1bf4e5ad1a63369f260800000000000000009f2701009f101400000000000000000000000000000000000000009f36020000820200009f370400000000
- base10: 3744195857129067327425457965371392000013746636766901465671364195589258867032803844929099232440961730570073818492968473360222224256882860021510446449227970742743564393062400000000000000000447974065558692040000000000000000000000000000000000000000000000001591520184777415116800175058639126528000
- base45: X G.M8E+A-A6A3EO:0112100K48G0BPD2PD2PD2PD2YJQPA8PA8PA8PA8O1A%P6-E0O6CAQG14W- UVS7K9BL/0UYB8/UY*LIOCH5KN01000000000O30+-4O30L12000000000000000000000000000000X5KHB0+20HB0O30:.6000000
- base64: hQVDUFYwMWFvTwfUEAAAAUAQVxMSNBI0EjQSNNEjQSNBI0EjQSNPXzQBAp9gEoMs/dXzyzxqWKwHpF0b9OWtGmM2nyYIAAAAAAAAAACfJwEAnxAUAAAAAAAAAAAAAAAAAAAAAAAAAACfNgIAAIICAACfNwQAAAAA
- base94: +bwW=PXyQ3m_Bw8Bg2J$V2%i.wHbv$wHbv$TyIyMN4f~.8[f~.J`J1,ekX]5,]=TW'nA}-,5C]"M^g[Usm$?61sXd"!!!!!`HU-!7hT-!!!!!!!!!!!!!!!!!!!!!!!!!!1?z4CA99+!;tU-!!!!!!



이번에도 가장 작은 버전과 그중 가장 짧은 인코딩 길이를 갖는 base45가 제일 우수해요. 반면 base64는 가장 큰 버전을 사용해서 크기로 따져보면 가장 비효율 적이에요. base45는 base64와 20자 밖에 차이가 나지 않기 때문에 충분히 대안으로 생각해볼만 하죠.
구현
base10, base45, base94 인코딩을 직접 구현해봤어요. bqencode 리파지토리에서 확인하실 수 있어요.
encode(input: string | Buffer): string {
let result = "";
const buf = Buffer.isBuffer(input) ? input : Buffer.from(input);
for (let i = 0; i < buf.length; i += 2) {
if (i + 1 < buf.length) {
let val = buf.readUint16BE(i);
for (let j = 0; j < 3; j++) {
result += this.charset.charAt(val % 45);
val = Math.floor(val / 45);
}
} else {
let val = buf.readUint8(i);
for (let j = 0; j < 2; j++) {
result += this.charset.charAt(val % 45);
val = Math.floor(val / 45);
}
}
}
return result;
}
decode(str: string): Buffer {
if (!this.isBase45(str)) {
throw new InvalidEncodingError();
}
if (str.length === 0) {
return Buffer.alloc(0);
}
const input = Array.from(str).map((c) => this.charset.indexOf(c) as number);
const result: number[] = [];
for (let i = 0; i < str.length; i += 3) {
if (i + 2 < str.length) {
const val = input[i] + input[i + 1] * 45 + input[i + 2] * 45 ** 2;
result.push(val >> 8, val & 0xff);
} else {
const val = input[i] + input[i + 1] * 45;
result.push(val);
}
}
return Buffer.from(result);
}
같이 보기
- ISO/IEC 18004:2024: QR 사양. 하지만 비싸기 때문에 전 나라표준인증에서 2000년 버전(KS X ISO/IEC18004)을 참고했어요.
- QR 바이너리 인코딩 구현: https://github.com/dimipay/bqencode
- QR code on Wikipedia: https://en.wikipedia.org/wiki/QR_code
- QR version on qrcode.com: https://www.qrcode.com/en/about/version.html
- RFC9285: https://www.rfc-editor.org/rfc/rfc9285
- Efficient QR codes: https://www.imperialviolet.org/2021/08/26/qrencoding.html
'디미페이' 카테고리의 다른 글
| SOLID 디미페이 (10) | 2025.01.13 |
|---|---|
| Local Token 0.4 Release Note (9) | 2024.11.24 |
| 🤫오프라인이지만 온라인이어야 해요 - 로컬 생성 결제 토큰 (15) | 2024.10.05 |
| 🔩Nest.js로 견고한 백엔드 만들기 (8) | 2024.10.01 |
| 🐣백지에서 시작하는 디미페이 v2 백엔드 리팩터링 (12) | 2024.09.28 |



